

{kind=link}
Black Forest Labs, one of many world’s main AI analysis labs, simply modified the sport for picture era.
The lab’s FLUX.1 picture fashions have earned world consideration for delivering high-quality visuals with distinctive immediate adherence. Now, with its new FLUX.1 Kontext mannequin, the lab is basically altering how customers can information and refine the picture era course of.
To get their desired outcomes, AI artists at present typically use a mix of fashions and ControlNets — AI fashions that assist information the outputs of a picture generator. This generally includes combining a number of ControlNets or utilizing superior methods just like the one used within the NVIDIA AI Blueprint for 3D-guided picture era, the place a draft 3D scene is used to find out the composition of a picture.
The brand new FLUX.1 Kontext mannequin simplifies this by offering a single mannequin that may carry out each picture era and enhancing, utilizing pure language.
NVIDIA has collaborated with Black Forest Labs to optimize FLUX.1 Kontext [dev] for NVIDIA RTX GPUs utilizing the NVIDIA TensorRT software program growth equipment and quantization to ship quicker inference with decrease VRAM necessities.
For creators and builders alike, TensorRT optimizations imply quicker edits, smoother iteration and extra management — proper from their RTX-powered machines.
The FLUX.1 Kontext [dev] Flex: In-Context Picture Era
Black Forest Labs in Might launched the FLUX.1 Kontext household of picture fashions which settle for each textual content and picture prompts.
These fashions permit customers to start out from a reference picture and information edits with easy language, with out the necessity for fine-tuning or complicated workflows with a number of ControlNets.
FLUX.1 Kontext is an open-weight generative mannequin constructed for picture enhancing utilizing a guided, step-by-step era course of that makes it simpler to regulate how a picture evolves, whether or not refining small particulars or remodeling a whole scene. As a result of the mannequin accepts each textual content and picture inputs, customers can simply reference a visible idea and information the way it evolves in a pure and intuitive method. This permits coherent, high-quality picture edits that keep true to the unique idea.
FLUX.1 Kontext’s key capabilities embody:
- Character Consistency: Protect distinctive traits throughout a number of scenes and angles.
- Localized Enhancing: Modify particular parts with out altering the remainder of the picture.
- Fashion Switch: Apply the appear and feel of a reference picture to new scenes.
- Actual-Time Efficiency: Low-latency era helps quick iteration and suggestions.
Black Forest Labs final week launched FLUX.1 Kontext weights for obtain in Hugging Face, in addition to the corresponding TensorRT-accelerated variants.

Historically, superior picture enhancing required complicated directions and hard-to-create masks, depth maps or edge maps. FLUX.1 Kontext [dev] introduces a way more intuitive and versatile interface, mixing step-by-step edits with cutting-edge optimization for diffusion mannequin inference.
The [dev] mannequin emphasizes flexibility and management. It helps capabilities like character consistency, type preservation and localized picture changes, with built-in ControlNet performance for structured visible prompting.
FLUX.1 Kontext [dev] is already out there in ComfyUI and the Black Forest Labs Playground, with an NVIDIA NIM microservice model anticipated to launch in August.
Optimized for RTX With TensorRT Acceleration
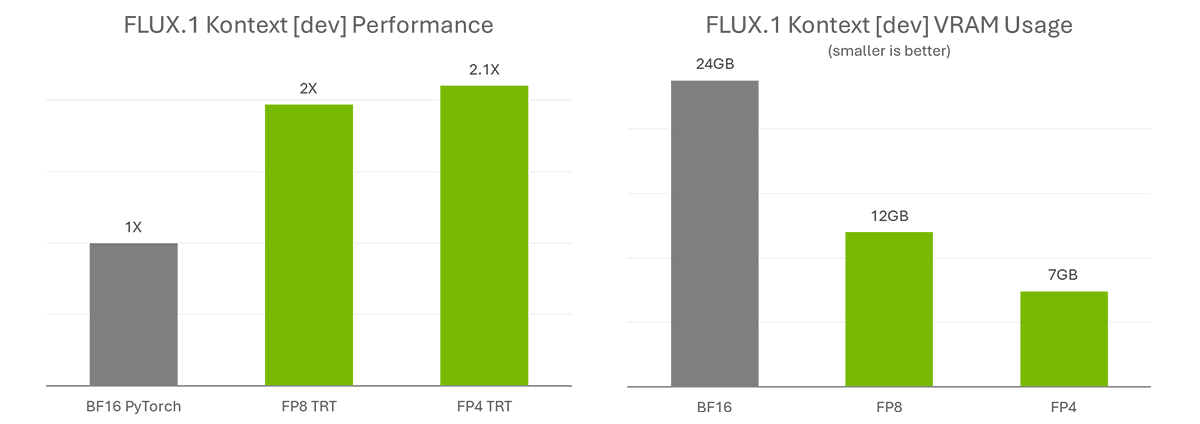
FLUX.1 Kontext [dev] accelerates creativity by simplifying complicated workflows. To additional streamline the work and broaden accessibility, NVIDIA and Black Forest Labs collaborated to quantize the mannequin — decreasing the VRAM necessities so extra individuals can run it regionally — and optimized it with TensorRT to double its efficiency.
The quantization step permits the mannequin measurement to be diminished from 24GB to 12GB for FP8 (Ada) and 7GB for FP4 (Blackwell). The FP8 checkpoint is optimized for GeForce RTX 40 Sequence GPUs, which have FP8 accelerators of their Tensor Cores. The FP4 checkpoint is optimized for GeForce RTX 50 Sequence GPUs for a similar purpose and makes use of a brand new methodology known as SVDQuant, which preserves excessive picture high quality whereas decreasing mannequin measurement.
TensorRT — a framework to entry the Tensor Cores in NVIDIA RTX GPUs for optimum efficiency — supplies over 2x acceleration in contrast with operating the unique BF16 mannequin with PyTorch.
Be taught extra about NVIDIA optimizations and learn how to get began with FLUX.1 Kontext [dev] on the NVIDIA Technical Weblog.
Get Began With FLUX.1 Kontext
FLUX.1 Kontext [dev] is on the market on Hugging Face (Torch and TensorRT).
AI fans excited by testing these fashions can obtain the Torch variants and use them in ComfyUI. Black Forest Labs has additionally made out there an on-line playground for testing the mannequin.
For superior customers and builders, NVIDIA is engaged on pattern code for simple integration of TensorRT pipelines into workflows. Try the DemoDiffusion repository to return later this month.
However Wait, There’s Extra
Google final week introduced the discharge of Gemma 3n, a brand new multimodal small language mannequin ultimate for operating on NVIDIA GeForce RTX GPUs and the NVIDIA Jetson platform for edge AI and robotics.
AI fans can use Gemma 3n fashions with RTX accelerations in Ollama and Llama.cpp with their favourite apps, akin to AnythingLLM and LM Studio.
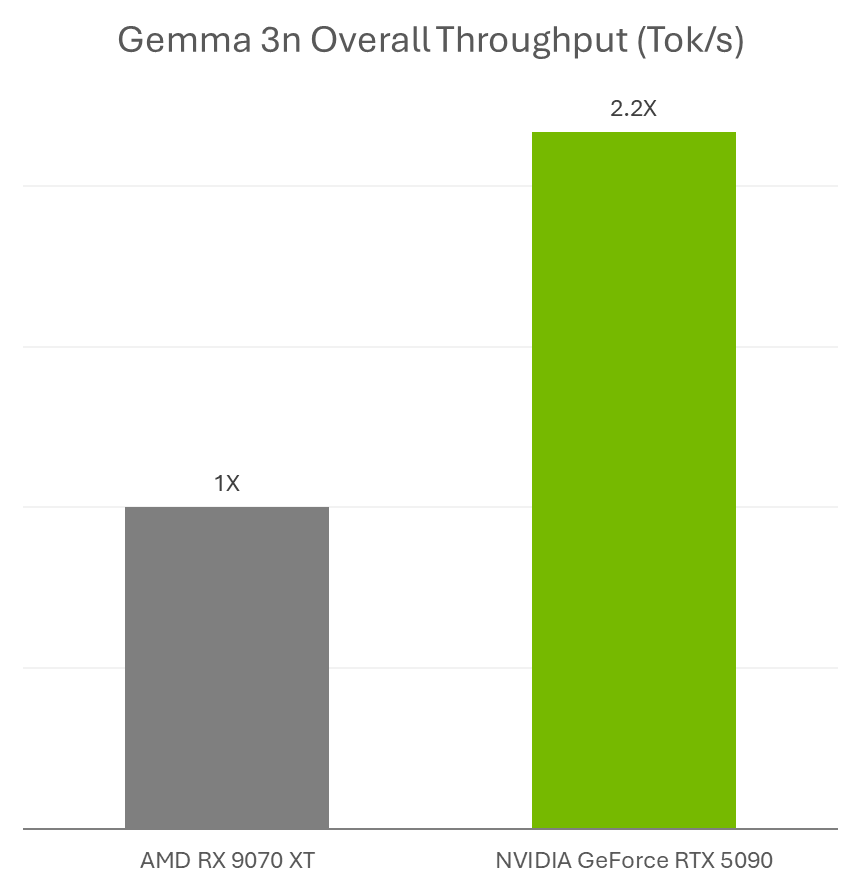
Plus, builders can simply deploy Gemma 3n fashions utilizing Ollama and profit from RTX accelerations. Be taught extra about learn how to run Gemma 3n on Jetson and RTX.
As well as, NVIDIA’s Plug and Play: Undertaking G-Help Plug-In Hackathon — operating nearly by means of Wednesday, July 16 — invitations builders to discover AI and construct customized G-Help plug-ins for an opportunity to win prizes. Save the date for the G-Help Plug-In webinar on Wednesday, July 9, from 10-11 a.m. PT, to be taught extra about Undertaking G-Help capabilities and fundamentals, and to take part in a stay Q&A session.
Be part of NVIDIA’s Discord server to attach with neighborhood builders and AI fans for discussions on what’s potential with RTX AI.
Every week, the RTX AI Storage weblog collection options community-driven AI improvements and content material for these seeking to be taught extra about NVIDIA NIM microservices and AI Blueprints, in addition to constructing AI brokers, artistic workflows, digital people, productiveness apps and extra on AI PCs and workstations.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC e-newsletter.
Comply with NVIDIA Workstation on LinkedIn and X.
See discover concerning software program product data.